Parsing
Parsing is the task of recognizing a sentence and assigning a structure to it. The structure can look like a phrase tree, or it can look like a network of word to word dependencies.

Overview
Parsing studies sentence structure. Constituency parsing organizes words into nested phrases. Dependency parsing asks which word depends on which other word. Both help NLP systems move from raw word order to interpretable grammatical relationships.
A sentence is not only a sequence. Human language works because words compose into larger units, and those units carry meaning. If we want to interpret language correctly, we need to know what is connected to what.
This is why parsing became such a central idea in classical NLP. It gives language an intermediate representation. Before a system translates, extracts information, answers questions, or checks grammar, it can first recover the sentence structure.
Two views of syntactic structure
There are two major ways to represent syntax. Constituency structure treats language as phrases inside phrases. Dependency structure treats language as directed relations between words. The first view asks how words form units. The second asks which word governs another.

The comparison is useful because the two approaches are good at different things. Constituency parsing is often useful for grammar checking, text generation, translation, and question answering. Dependency parsing is usually faster and especially useful for information extraction because it directly exposes relations such as subject, object, modifier, and case.
Constituency parsing
Constituency parsing is also called phrase structure parsing. It starts with words, gives them categories such as determiner, adjective, noun, verb, or preposition, then combines them into larger phrases.
For example, “the cuddly cat” can become a noun phrase. “by the door” can become a prepositional phrase. Those phrases can then combine again into a larger noun phrase such as “the cuddly cat by the door.” The important idea is recursion. Small structures can become part of bigger structures.
NP → Det Adj N
PP → P NP
NP → NP PP
Context free grammar
A context free grammar is a formal system for modeling constituency structure. It contains nonterminal symbols, terminal symbols, grammar rules, and a start symbol. In plain language, it tells the parser which phrase patterns are allowed.
S → NP VP
VP → Vi
VP → Vt NP
VP → VP PP
NP → DT NN
NP → NP PP
PP → IN NP
A derivation applies these rules until the sentence is produced. The derivation can be drawn as a parse tree. A sentence belongs to the grammar if at least one derivation can produce it.
Ambiguity
The beautiful and annoying part is that one sentence can have more than one parse tree. “The man saw the dog with the telescope” can mean that the man used the telescope, or that the dog had the telescope. The words are the same. The structure is not.
Classical parsing becomes hard because real sentences can have a very large number of possible parses. If the grammar is too strict, it misses valid sentences. If the grammar is too loose, it produces too many structures and gives us no easy way to choose the right one.
Probabilistic parsing
Statistical parsing tries to solve this selection problem by learning from treebanks. A treebank is a collection of sentences paired with their parse trees. Instead of writing every grammar preference by hand, the system can estimate how often each rule appears in annotated data.
A probabilistic context free grammar adds probabilities to the grammar rules. The probability of a parse tree is the product of the probabilities of the rules used to build it. Then parsing becomes a search problem: given a sentence, find the highest scoring parse tree.
CFG tells us which trees are possible. PCFG helps us decide which possible tree is more likely.
CKY algorithm
The CKY algorithm is a dynamic programming method for parsing with a grammar in Chomsky normal form. It does not guess the entire tree at once. It fills a chart over spans of the sentence, starting from single words and building larger constituents.
Each chart cell stores the best score for a nonterminal that can cover a span. Backpointers are also stored, so the parser can recover the actual tree after finding the best score for the full sentence.
π(i, j, X)
= best score for a parse tree covering words i through j with root X
Dependency parsing
Dependency parsing uses a more direct representation. It shows which words depend on which other words. A dependent may modify its head, or it may serve as an argument of its head.
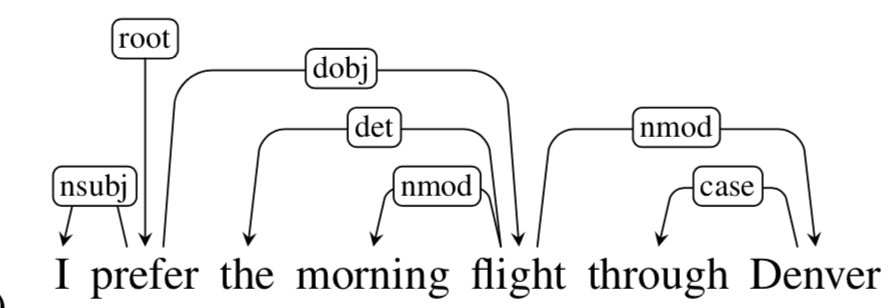
In “I prefer the morning flight through Denver,” the verb “prefer” functions as the central head. “I” is the nominal subject. “flight” is the object. “the” is a determiner. “morning” modifies “flight.” “through Denver” attaches through a case relation and a nominal modifier relation.
Dependency relations
Dependency labels make the relation explicit. They do not only say that two words are connected. They say how they are connected.
Nominal subject
Direct object
Indirect object
Determiner
Nominal modifier
Adjectival modifier
Preposition or case marker
Conjunct
Why structure is useful
Parsing is useful because many language tasks depend on relations, not just words. Translation needs structure because languages can have different word orders. Information extraction needs structure because it must know which entity did which action. Question answering needs structure because the answer may depend on subject, object, modifier, or attachment.
This is also why dependency parsing feels especially practical. It gives a compact map of grammatical relations. For many downstream tasks, that map is easier to use than a full phrase structure tree.
Limits of probabilistic grammars
PCFGs are elegant, but they have a weakness: they can ignore the actual words too much. Two parses may differ only by whether a prepositional phrase attaches to a verb phrase or a noun phrase. A plain PCFG may decide using rule probabilities without looking carefully at the lexical content.
Lexicalized PCFGs respond to this by adding headwords to trees. Each rule has a special child that acts as the head. This gives the grammar more sensitivity to the words that control the structure.
Reflection
The main lesson for me is that parsing makes language less blurry. Constituency parsing shows how words become phrases. Dependency parsing shows how words govern and modify one another. PCFGs bring probability into the picture, and CKY gives a clean algorithmic way to search over possible structures.
In the LLM era, parsing still feels conceptually important. Large models may learn many syntactic patterns implicitly, but parsing gives us a visible structure to inspect. It reminds me that fluency and structure are related, but they are not identical.