Model Evaluation
A page about why evals matter, how benchmarking actually works, and why model confidence is often a measurement problem before it is a modeling problem.
What drew me into evaluation is that it sits in an uncomfortable but important place between research and product. We all want to say a model is good, robust, or reliable. But the moment you ask “good according to what?” the real work begins. That is where evals become less like a side task and more like the discipline that keeps the rest of the system honest.

Overview
Evals matter because AI systems are probabilistic, messy, and failure-prone in ways that ordinary software tests do not fully capture. Good evaluation makes model behavior legible. It tells us not only whether something works, but where it breaks, how confidently it breaks, and whether the benchmark we chose is actually measuring the thing we care about.[1]
I like thinking about evals not as a final scoreboard, but as an instrument. An instrument is only useful when it is measuring the right object. That is why evaluation is harder than it first appears. It is not only about numbers. It is about operationalizing judgment.
That is also why the recent conversation around evals feels so important. As Lenny’s interview with Hamel Husain and Shreya Shankar frames it, evals have become a central skill for AI builders because they provide the structure that moves teams beyond intuition, demos, and vague “it feels better” thinking.[1]
Why evals became such a big deal
Traditional software can often be tested through deterministic rules. An LLM product usually cannot. The same prompt can yield different outputs, the same answer can be judged differently across contexts, and many failures are not syntax errors but judgment errors. That changes the development loop.
This is why evals feel so central now. They serve as a bridge between model behavior and product standards. They make teams define what quality actually means, and they force a more honest conversation about tradeoffs: precision versus coverage, benchmark performance versus real-world usefulness, and automated metrics versus human judgment.[1]
The most interesting thing to me is that evals are not just about catching failure. They are also about shaping taste. The benchmark you choose reveals what kind of intelligence you think matters.
Benchmarking and what it really measures
A benchmark is useful because it gives you a stable reference point. But it also narrows the world. The moment you choose a benchmark, you choose which behaviors count and which ones stay invisible. That is why benchmarking is helpful and dangerous at the same time.
In practice, benchmarking often starts from a clean unit of comparison: same prompt format, same question set, same scoring rule. That cleanliness is valuable. But if you only optimize for benchmark scores, you can quietly drift away from the real task. A model can become good at a benchmark’s shape without becoming good at the broader capability the benchmark is meant to proxy.
ARC-Challenge
View Benchmarking Repo ↗One benchmark I keep returning to is ARC-Challenge. The ARC dataset was introduced as a collection of grade-school science multiple-choice questions designed to test reasoning more seriously than easier QA tasks. The dataset card describes ARC as containing 7,787 science questions, partitioned into an Easy set and a Challenge set, where the Challenge questions are the ones missed by both a retrieval-based baseline and a word co-occurrence baseline.[2][3]
That design choice is exactly what makes ARC-Challenge interesting. It is not merely trivia. It tries to filter out the questions that are too easy to solve by shallow lexical shortcuts. The Hugging Face dataset card lists the ARC-Challenge splits as 1,119 training examples, 299 validation examples, and 1,172 test examples.[2]
It gives a clean multiple-choice evaluation setting, but it still resists the illusion that QA is solved. The benchmark is compact enough to inspect carefully and difficult enough to expose reasoning weaknesses.[2][3]
At the same time, I do not think a benchmark should be treated as the capability itself. ARC-Challenge is powerful as a test bed, but it remains a narrow frame. It measures one slice of reasoning under one particular output format.
Metrics, overlap, and approximation
One reason evaluation gets confusing is that different metrics reflect different philosophies of correctness. Some reward exact overlap. Some reward softer resemblance. Some try to approximate semantic faithfulness through embeddings.
Perplexity
Perplexity is one of the classic intrinsic metrics for language models. It measures how surprised a model is by the next tokens in real text. Lower perplexity usually means the model assigns higher probability to correct continuations, so in general: lower is better.
I think of perplexity as a fluency and prediction metric rather than a full quality metric. A model can achieve low perplexity while still being weak at reasoning, factuality, or instruction following.

Perplexity is hard to compare across models with different tokenizers, vocabularies, or context windows. It also changes across datasets, and it may penalize alternative phrasings that are still valid. Most importantly, low perplexity does not guarantee truthfulness, creativity, or good reasoning.
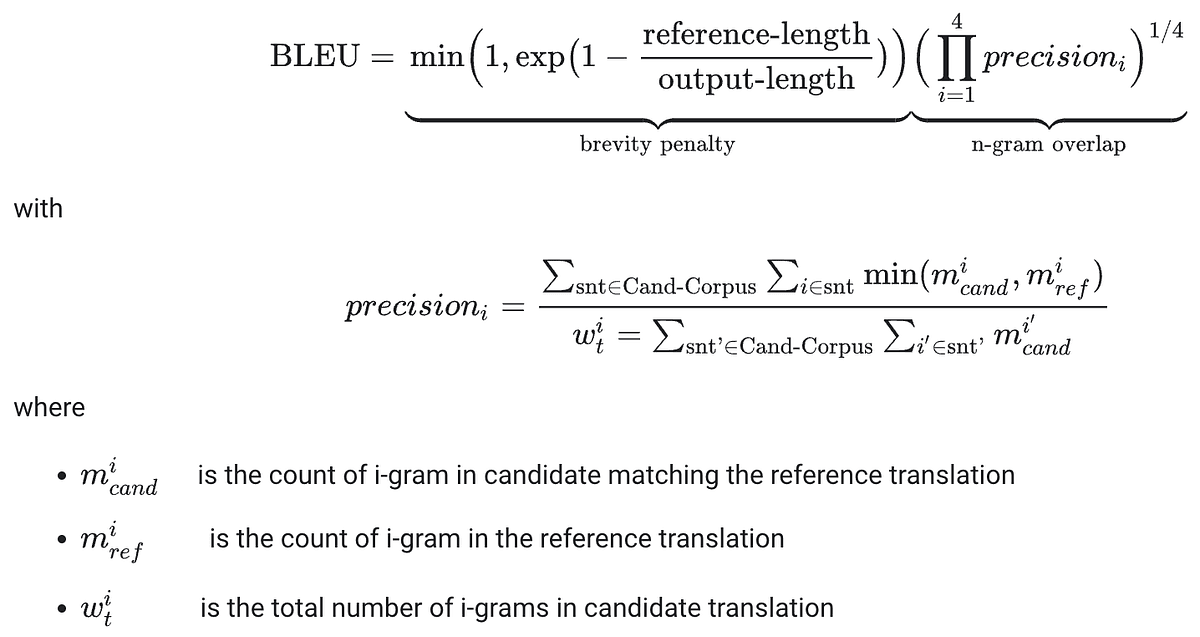
BLEU
BLEU is useful when you want a compact overlap-based signal between a candidate text and a reference. I think of it as a precision-oriented metric: how much of what was generated also appears in the reference? It can be informative, but it is also easy to over-trust, especially when multiple valid phrasings exist.
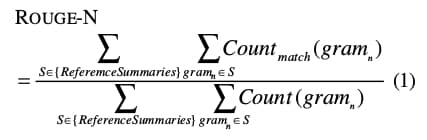
ROUGE
ROUGE becomes more natural when the task is summarization or recall-heavy generation. It asks how much of the reference content is recovered by the candidate. That shift in emphasis sounds small, but it changes what the metric rewards.
BERTScore
Metrics such as BERTScore try to move past raw token overlap by comparing contextual embeddings. I find that move conceptually appealing because it better matches how we often judge language: two answers can differ in wording and still feel semantically close.
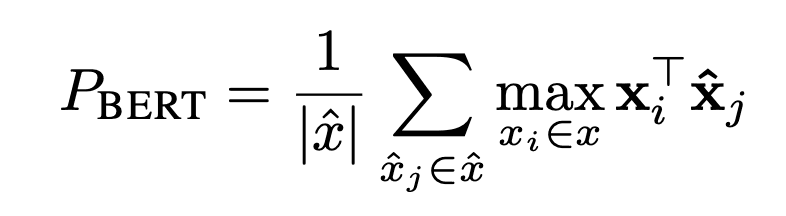
None of these metrics is enough by itself. The main lesson, at least for me, is that evaluation quality depends on matching the metric to the task rather than asking one metric to stand in for all forms of correctness.
Logprobs and confidence
One of the most useful things I learned is that model evaluation does not stop at the final answer token. Sometimes the most informative signal is the model’s distribution over possible outputs.
OpenAI’s logprobs guide explains that when log probabilities are returned, you can inspect the likelihood assigned to each output token, compute sequence scores by summing token logprobs, and use those values for ranking, classification confidence, or retrieval self-evaluation.[4]
That matters because confidence is often hidden in generative systems. A model may produce one label, but its token distribution can reveal whether that choice was sharp or fragile. The OpenAI cookbook specifically highlights logprobs as useful for classification confidence thresholds and retrieval-style self-evaluation.[4]
Accuracy only tells you whether the answer was right. Logprobs can tell you how strongly the model leaned toward that answer, what alternatives it considered plausible, and whether selective evaluation based on confidence might improve the system’s effective reliability.[4]
I think this is especially powerful in multiple-choice benchmarking. A hard benchmark like ARC-Challenge already gives a clean correctness signal. Adding logprob-based confidence lets you ask a second question: not just whether the model answered correctly, but whether it knew when it was uncertain.
Reflection
The longer I spend with evaluation, the less I think of it as bookkeeping. It feels closer to measurement theory. Every eval encodes a view about what matters, every benchmark hides some assumptions, and every metric reveals only a slice of model behavior.
That is why I find evals genuinely interesting. They are not just there to verify the model after the “real work” is done. They are part of the real work. They determine what progress even means.
For me, ARC-Challenge, overlap metrics, embedding-based metrics, and logprob-aware scoring all point to the same deeper lesson: evaluation is not about finding one perfect number. It is about building a structured view of model behavior that is sharp enough to support judgment.
Sources
Lenny Rachitsky. (2025). Why AI evals are the hottest new skill for product builders.
Hugging Face. (n.d.). allenai/ai2_arc dataset card.
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., Tafjord, O., Turney, P., & Khashabi, D. (2018). Think you have solved question answering? Try ARC.
OpenAI. (n.d.). Using logprobs.